| 들어가며
생성형 AI의 학습에 병렬 연산 구조의 프로세서가 더 효율적인 성과를 보여주어 GPU 컴퓨팅이 부각되었습니다. 그리고 AI 학습 데이터 량의 기하급수적 증가로 메모리의 데이터 작업에 있어 높은 수준의 대역폭(bandwidth)이 요구되면서 HBM이 그 역할을 담당하게 되었죠. 1대의 서버 단위를 넘어 AI 데이터센터 차원으로 생각을 확장해보면, AI의 발전에 따라 여러 대의 서버 각각에 있는 여러 개의 GPU가 학습을 동시에 진행하면서 이제 서버간의 데이터 트래픽 문제가 부상하고 있습니다.
여러 대의 서버 사이에 데이터가 더 많이, 더 빨리 오고 가려면 어떻게 해야할까요?
| Contents
1. 데이터센터 서버 개요
2. 서버간 데이터 트래픽 증가
3. 서버간 데이터 병목 현상 해결방안
4. 결론 : NVDA, AVGO, TSM
Dall-E가 표현한 데이터센터 내부

1. 데이터센터 서버 개요
데이터센터 서버의 구조는 컴퓨터와 유사합니다. 컴퓨터의 CPU는 캐쉬메모리만 가지고 있고 대부분 데이터처리는 DRAM이 담당합니다. CPU와 DRAM은 시스템 버스(system bus)로 연결되어있고, CPU와 DRAM 이외 나머지 하드웨어(GPU, NIC, SSD, HDD)는 PCIe(Peripheral Component Interconnect express)로 연결되어있습니다. 생성형 AI 발달에 따라 파라미터의 개수가 기하급수적으로 커지고 있는데요. 사이즈가 워낙 커지다 보니 여러 개의 GPU가 나눠서 학습을 해야하는 상황이 되었고, 이로 인해 각 서버의 GPU간 데이터 송수신 횟수가 증가했습니다.
이는 생성형 AI와 같은 인공 신경망을 서버로 구현할 경우 여러 서버들이 병렬적 역할을 하게 된다는 의미입니다.
2. 서버간 데이터 트래픽 증가
서버간 데이터 트래픽이 증가한 이유는 1) AI 학습에 필요한 데이터 세트 증가, 2) 이들 데이터 세트를 개별 서버에 학습시키고 각각의 학습 결과물을 다시 병합하는 과정에서 발생하는 데이터 이동량 증가 입니다.
데이터 트래픽은 도로에 비유하자면 도로 위에 자동차가 너무 많아서 교통정체가 발생하는 상황과 유사합니다. 교통정체를 해소하려면 길을 넓히고(대역폭) 자동차가 빨리빨리(속도) 길에서 빠져나가줘야겠죠. 서버간 데이터 이동이 가장 빠른 것은 서버간 직접 연결입니다.
그러나 모든 서버가 직접 연결될 수는 없기 때문에 '서버 스위치'라는 장치가 필요합니다. 서버 스위치는 자동차가 달리는 도로에 있는 고가도로로 비유할 수 있습니다. 서버 스위치는 데이터의 고가다리 역할을 하여 혼잡성을 줄여주는데, 그 대신 직접 연결 대비 번거로운 전송 과정을 거치게 됩니다. 데이터 트래픽이 일정 수준을 초과하면 병목 현상이 발생할 개연성이 있는 지점입니다.

AI 학습의 오류는 GPU-메모리, 서버-서버간 데이터 이동에서 발생하는 데이터 손실 등에 기인합니다. GPU-메모리 사이의 문제를 HBM이 해결하면서 GPU-메모리간 병목 현상은 어느 정도 해소되었습니다. 그러나 HBM의 기여로 GPU의 연산 처리가 더욱 빨라진 만큼 서버-서버간 데이터 트래픽 병목 현상도 기존 대비 개선된 방식의 해결책이 요구될 것으로 예상됩니다.
3. 서버간 데이터 병목 현상 해결방안
(1) 시스템적 접근 : DPU, SuperNIC
기존 NIC(Network Interface Card)의 역할은 서버 간의 단순 데이터 전송 기능에 그쳤습니다. 서버간 데이터 이동은 이더넷 기반 TCP/IP 프로토콜을 통해 이루어지는데, 서버 내부 데이터를 해당 프로토콜로 변환하여 타 서버로 전송하는 방식이죠. 기존 데이터센터 서버는 프로토콜 변환 과정에 CPU가 사용되었습니다. 그러나 AI 시대에 접어들어 데이터 트래픽이 증가하면서 기존의 NIC-CPU 체계로는 감당이 안되는 상황이 벌어졌습니다. 그래서 CPU의 작업 부담을 덜어주는 DPU(Data Processing Unit), 네트워크를 가속하는 Super NIC의 중요성이 커졌습니다.
엔비디아에 따르면, DPU 버전 업그레이드만으로 메모리 대역폭(bandwidth)이 4.2배, 컴퓨팅 파워는 4배 증가한다고 합니다. DPU와 SuperNIC 시장에서는 엔비디아와 브로드컴이 기술 경쟁을 벌이고 있습니다. 이들 장치 내부에는 ARM 코어를 활용한 컴퓨팅 블록, 주메모리(DRAM), 인터페이스 칩 모두를 갖추고 있어 앞으로 반도체 업계 전반의 낙수 효과도 기대해볼만 합니다. DPU는 CPU, GPU 다음으로 중요성이 올라가고 있는 프로세서 입니다.
[참고1] 엔비디아의 PXN 기술
NVSWITCH(NVIDIA interconnect fabric chip)을 이용한 PXN 기술을 이용할 경우 서버-서버간 데이터 전송 경로가 기존 4회 대비 2회 단축되는 효과가 발생합니다. 예를 들어 서버1의 GPU1에서 서버2의 GPU3으로 데이터가 이동한다고 한다면, 기존에는 서버1 GPU1 > 리프스위치1 > 스파인스위치3 > 리프스위치3 > 서버2 GPU 경로로 이동해야 했습니다. 그런데 PXN 기능 사용 시 이 경로가 서버1 GPU1 > 리프스위치3 > 서버2 GPU 로 단축되는 효과가 나타납니다. GPU가 많고 네트워크가 복잡한 데이터센터일수록 그 효과는 더욱 큰 효익을 가져오는 것으로 나타났습니다.

(2) 물리적 접근
2-1) 광섬유 케이블의 필요성
빅테크들은 엔비디아의 PXN 기술을 사용하지 않더라도, 이와 유사한 fabric chip을 이용하여 데이터 이동 경로를 줄이려는 시도를 할 것으로 보입니다. 이러한 형태의 기술은 서버-스위치 연결의 평균 길이가 증가하는 결과를 초래하는데요.(fabric chip을 이용하면 리프스위치 숫자가 기존 대비 더 많아지는 것으로 추정되는데, 이 부분은 별도 확인이 필요합니다) 거리가 짧을 때는 구리 기반의 케이블을 사용하면 됩니다만, 거리가 멀어질수록 신호손실이 많아지는 관계로 장거리에서 손실이 적은 광섬유 케이블(optical fiber cable)을 사용해야 합니다. 광섬유 케이블 Q 증가, 광신호 처리용 반도체칩 P, Q 증가를 예상해볼 수 있는 지점입니다.

2-2) 광신호 연결(optical interconnects)의 문제점
광신호를 전기신호로 전환하는 과정에서 발생하는 전력소모, 전환된 전기신호를 스위치칩 또는 프로세서(XPU)로 전송하는 과정에서 발생하는 신호손실이 주요 문제점입니다. 이에 대한 해결책은 2가지 입니다.
첫째, 신호 전환 과정에서 발생하는 전력소모를 줄이기 위한 실리콘 포토닉스와 LPO(Linear-drive Pluggable Optics)
둘째, 신호 전송 과정에서 발생하는 신호손실을 줄이기 위해 프로세서(XPU)와의 물리적 간격을 좁히기 위한 CPO(Co-Packaged Optics)

2-3) 전력손실 문제 해결책1 : 실리콘 포토닉스
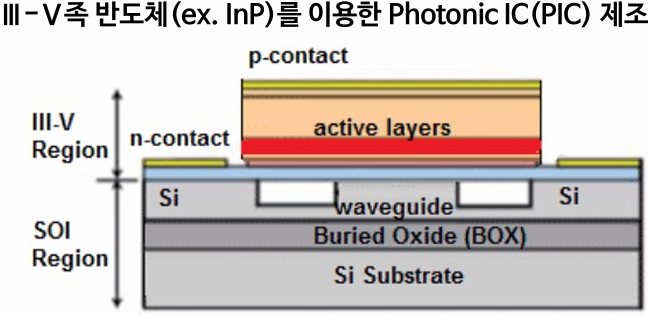
광신호를 전기신호로 바꾸는 과정에서는 광학과 전자기학 2가지를 모두 고려해야 하는데, 실리콘 포토닉스 기술을 이용하면 이 과정에서 전력손실과 신호손실을 동시에 줄일 수 있습니다. 실리콘 포토닉스는 SOI(Silicon On Insulator) 위에 InP(인듐인)를 올리는 방식으로 구현하는데, InP를 통해 전기신호가 광신호로 전환되고, 전환된 광신호가 SI substrate 양옆의 빈 공간에 있는 공기층보다 굴절률이 높은 waveguide로 향하면서 신호가 전송되는 원리입니다. 문과생으로서 와닿는 내용은 아니군요. 아무튼 실리콘 포토닉스 기술을 이용한 PIC(Photonic Integrated Circuit), EIC(Electric Integrated Circuit)를 FOWLP 공정으로 결합한 것이 브로드컴의 TH5-Bailly 입니다.
2-3) 전력손실 문제 해결책2 : LPO(Linear-drive Pluggable Optics)
LPO는 전력 소모량이 많은 DSP(Digital Signal Processor) 장치를 생략할 수 있어 꾸준히 시도되고 있습니다. DSP는 아날로그 신호를 디지털 신호로 변화하는 과정에서 일부 손상된 신호를 깔끔하게 다듬는 역할을 담당합니다.

2-4) 신호손실 문제 해결책 : CPO(Co-Packaged Optics)
신호손실을 줄이려면 물리적 간격을 최소화하기 위해 프로세서(XPU)와 광학칩(optic IC)를 공동패키징하는 기술이 필요합니다. 신호손실이 발생하는 지점은 다음의 4가지 입니다.
첫째, 광신호가 광학칩으로 들어와 전기신호로 변환된 후 DSP와 같은 신호를 다듬어주는 칩까지 전송되는 구간
둘째, 광학모듈에서 프로세서(XPU)가 있는 PCB로 전달되는 구간
셋째, PCB 내부의 배선을 거치는 구간
넷째, substrate 또는 interposer를 거쳐 최종 도달해야 하는 프로세서(XPU)까지 가는 구간
신호의 전송 속도가 증가할수록 각 구간에서의 신호 손실률은 급격히 증가합니다. CPO를 사용하면 신호손실은 광신호가 전기신호로 변환되는 과정, 해당 신호가 프로세서(XPU)로 전달되는 과정에서만 발생하므로 손실률이 대폭 감소합니다. 향후 서버 간의 통신 속도 증가는 필수사항이므로 CPO 또한 필수적인 기술이라고 볼 수 있습니다. 앞서 언급한 브로드컴 TH5-Bailly는 실리콘 포토닉스, CPO 등을 모두 구현한 제품입니다.

[참고2] TSMC의 COUPE(Compact Universal Photonic Engine)
COUPE은 logic 칩에 하이브리드 본딩을 사용하는 SoIC 공정을 적용하여 PIC, EIC를 결합시킵니다. 그 결과 특정 주파수에서의 Impedance(저항) 특성이 단순 와이어본딩 대비 92%, TSV 본딩 대비 51% 개선되고, 이에 따라 단위 bit를 전송하는데 사용되는 전력이 타 공정 대비 40% 가량 감소합니다. TSMC는 서버-서버간 데이터 병목 현상을 해결하는 문제에 있어서도 기술 주도권을 가지고 있는 것으로 보입니다.
4. 결론 : NVDA, AVGO, TSM
어려운 얘기가 계속 나와 두통이 오지만 투자처는 결국 NVDA, AVGO, TSM으로 정리됩니다. 엔비디아와 브로드컴은 서로 경쟁하는 관계지만 TSMC는 양사의 제품을 모두 생산할 수 있는 위치라서 양사의 경쟁이 어느 방향으로 가던지 수혜를 누리는 회사입니다. 물론 3사 모두 다른 사업 부문의 비중이 훨씬 크기 때문에 상기의 내용 만으로 투자 아이디어를 설정하는 건 무리지만, AI 트렌드 전체를 겨냥하고 있으므로 시기를 조절하면 좋은 투자처가 될 것으로 보입니다.
광신호 연결 트렌드에 집중할 수 있는 종목은 Fabrinet(NYSE: FN) 입니다. 이 회사는 코히어런트, 루멘텀, 인피네라 등의 기업을 통하거나 직접 공급 방식으로 엔비디아와 빅테크 기업에 광섬유 케이블, 광학 케이블을 공급하고 있습니다. 사업별 매출 비중은 데이터 부문 42%, 통신 부문 37%, 자동차 11%, 기타 10%로 구성되어있고, 밸류에이션은 앞서 언급한 3사 대비 저렴한 편입니다. 그러나 현 시점에 앞서 언급한 3사보다 성장 기울기가 더 가파를지는 의문이고, 밸류에이션의 차이만큼 OPM의 차이가 있는 것을 보면 역시 시장의 평가에는 그만한 이유가 있는 것 같습니다.

* 참고자료
- AI era, HBM 다음 병목 찾기 (24-10-08 신영증권 강석용)
* Disclaimer
- 저는 이 글에서 다루는 업종에 속한 종목을 보유하고 있어 긍정 편향이 있을 수 있으며, 언제든지 관련 종목을 매매할 수 있습니다. 이 글은 투자를 추천하는 글이 아니며, 보유 종목이 속한 산업의 방향성을 검토하기 위해 작성한 글입니다. 정보 공유 차원에서 공개하지만 그 목적은 어디까지나 단순 정보 제공일 뿐입니다. 누군가 이를 근거로 투자를 했을 경우 발생할 수 있는 모든 일들에 대해 저는 법적 책임을 지지 않습니다. 또한, 이 글의 내용은 부정확한 내용과 오류를 포함하고 있을 수 있다는 점에 유의하여 주시기 바랍니다. 투자는 본인의 독립적인 리서치, 판단, 의사결정 등에 따라 이루어져야 하며, 투자의 책임은 전적으로 투자자 본인에게 귀속된다는 점을 기억해주시기 바랍니다.
Comments
Post a Comment